Previous: Information gathering on the WWW
Up: Information gathering on the WWW
Next: Example
Previous Page: Information gathering on the WWW
Next Page: Example
Previous: Information gathering on the WWW
Up: Information gathering on the WWW
Next: Example
Previous Page: Information gathering on the WWW
Next Page: Example
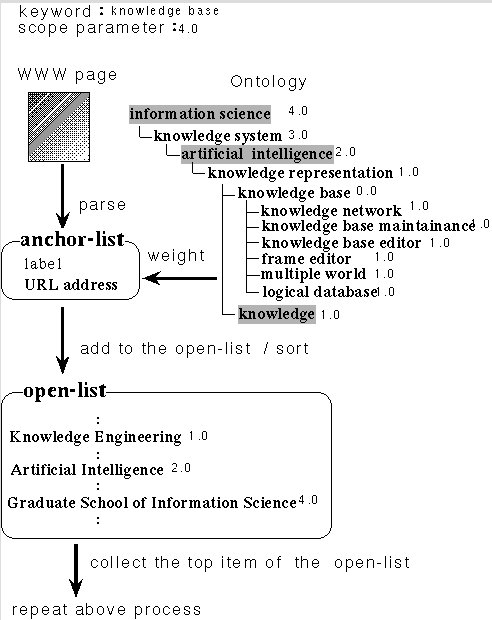
The algorithm is basically breadth-first searching. The difference is that IICA evaluates gathered pages and decides which anchor to access next. we show the algorithm as follows.
Receive a set of keywords, starting URL address, scope of reasoning context and number of pages to gathered from the user.
Match the keywords with terms in the ontology and list up terms relevant to the within the scope.
If the specified URL address exists in the close-list, search the page from the archive. Otherwise, retrieve the page by accessing HTTP.
If the number of pages is greater than the limit, exit the procedure. Otherwise, go to step5.
Parse the gathered page to extract URL addresses and labels in anchors and titles. If the addresses already exist in the open-list and close-list, discard them. Otherwise, add them to the open-list.
IF the terms listed up at step2 are included in the labels, score the labels using ontology. Otherwise, remove the label and the addresses from the open-list. Then Sort the open-list.
If there is no anchor in the page, pick up a URL address from the open-list. Then Go to step3.