Previous: Ontology-based intelligent information gathering
Up: IICA: An Ontology-based Internet Navigation System
Next: Information Extracting and Reorganization
Previous Page: Heuristics
Next Page: Information Extracting and Reorganization
Previous: Ontology-based intelligent information gathering
Up: IICA: An Ontology-based Internet Navigation System
Next: Information Extracting and Reorganization
Previous Page: Heuristics
Next Page: Information Extracting and Reorganization
Ontology-based text categorization is the classification of documents by using ontologies as category definition.
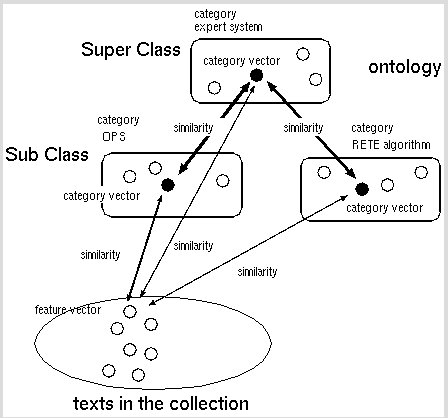
In our approach, the process of text categorization is twofold: (1) Text categorization by calculating similarity between a feature vector and a category vector, (2) Modifying weights between terms in a ontology by calculating similarity between category vectors (see Figure 5).
A feature vector is a vector which represents feature of a document, while a category vector is a vector which represents the characteristic of a category. The feature vector is calculated from the term frequency and the inverse document frequency The category vector is calculated from the feature vectors of the document assigned to the category.
We use vector space model commonly used in the information retrieval studies to weight terms and calculate feature vectors [8]. The algorithm is as follows:
The each initial category vector is calculated from the feature vector of the pages which is assigned to the category by matching keywords.